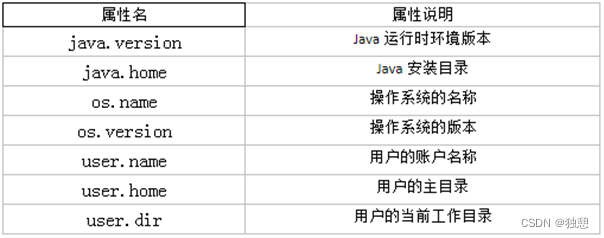
目录
简介
模型
设置
加载数据集
对数据进行标记
格式化数据集
建立模型
训练我们的模型
与变换器模型比较
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:使用 keras_nlp.layers.FNetEncoder 层对 IMDb 数据集进行文本分类。
简介
在本例中,我们将演示 FNet 在文本分类任务中取得与 vanilla Transformer 模型相当的结果的能力。我们将使用 IMDb 数据集,该数据集收集了贴有正面或负面标签的电影评论(情感分析)。
我们将使用 KerasNLP 中的组件来构建标记符和模型等。KerasNLP 让想要构建 NLP 管道的人的生活变得更轻松!:)
模型
基于变换器的语言模型(LM),如 BERT、RoBERTa、XLNet 等,已经证明了自注意机制在计算输入文本的丰富嵌入方面的有效性。然而,自注意机制是一种昂贵的操作,其时间复杂度为 O(n^2),其中 n 是输入中的标记数。因此,人们一直在努力降低自注意机制的时间复杂度,并在不影响结果质量的前提下提高性能。
2020 年,一篇名为《FNet:FNet: Mixing Tokens with Fourier Transforms》的论文,用一个简单的傅立叶变换层取代了 BERT 中的自我注意层,进行 "标记混合"。
这样做的结果是准确率相当,训练速度也加快了。论文中的几个要点尤为突出:
作者称,FNet 在 GPU 上比 BERT 快 80%,在 TPU 上比 BERT 快 70%。速度提升的原因有两个方面:a)傅立叶变换层是非参数化的,它没有任何参数;b)作者使用了快速傅立叶变换(FFT);这将时间复杂度从 O(n^2)(在自我关注的情况下)降低到 O(n log n)。
在 GLUE 基准测试中,FNet 的准确率达到了 BERT 的 92-97%。
设置
在开始执行之前,我们先导入所有必要的软件包。
!pip install -q --upgrade keras-nlp
!pip install -q --upgrade keras # Upgrade to Keras 3.import keras_nlp
import keras
import tensorflow as tf
import os
keras.utils.set_random_seed(42)我们还要定义超参数。
BATCH_SIZE = 64
EPOCHS = 3
MAX_SEQUENCE_LENGTH = 512
VOCAB_SIZE = 15000
EMBED_DIM = 128
INTERMEDIATE_DIM = 512加载数据集
首先,让我们下载并提取 IMDB 数据集。
!wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -xzf aclImdb_v1.tar.gz--2023-11-22 17:59:33-- http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
Resolving ai.stanford.edu (ai.stanford.edu)... 171.64.68.10
Connecting to ai.stanford.edu (ai.stanford.edu)|171.64.68.10|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 84125825 (80M) [application/x-gzip]
Saving to: ‘aclImdb_v1.tar.gz’aclImdb_v1.tar.gz 100%[===================>] 80.23M 93.3MB/s in 0.9s 2023-11-22 17:59:34 (93.3 MB/s) - ‘aclImdb_v1.tar.gz’ saved [84125825/84125825]样本以文本文件的形式存在。让我们来看看该目录的结构。
print(os.listdir("./aclImdb"))
print(os.listdir("./aclImdb/train"))
print(os.listdir("./aclImdb/test"))['README', 'imdb.vocab', 'imdbEr.txt', 'train', 'test']
['neg', 'unsup', 'pos', 'unsupBow.feat', 'urls_unsup.txt', 'urls_neg.txt', 'urls_pos.txt', 'labeledBow.feat']
['neg', 'pos', 'urls_neg.txt', 'urls_pos.txt', 'labeledBow.feat']该目录包含两个子目录:train 和 test。
每个子目录又包含两个文件夹:pos 和 neg,分别代表正面和负面评论。在加载数据集之前,我们先删除 ./aclImdb/train/unsup 文件夹,因为其中有未标记的样本。
!rm -rf aclImdb/train/unsup我们将使用 keras.utils.text_dataset_from_directory 实用程序从文本文件生成标有 tf.data.Dataset 的数据集。
train_ds = keras.utils.text_dataset_from_directory(
"aclImdb/train",
batch_size=BATCH_SIZE,
validation_split=0.2,
subset="training",
seed=42,
)
val_ds = keras.utils.text_dataset_from_directory(
"aclImdb/train",
batch_size=BATCH_SIZE,
validation_split=0.2,
subset="validation",
seed=42,
)
test_ds = keras.utils.text_dataset_from_directory("aclImdb/test", batch_size=BATCH_SIZE)Found 25000 files belonging to 2 classes.
Using 20000 files for training.
Found 25000 files belonging to 2 classes.
Using 5000 files for validation.
Found 25000 files belonging to 2 classes.现在我们将文本转换为小写。
train_ds = train_ds.map(lambda x, y: (tf.strings.lower(x), y))
val_ds = val_ds.map(lambda x, y: (tf.strings.lower(x), y))
test_ds = test_ds.map(lambda x, y: (tf.strings.lower(x), y))让我们打印几个样本。
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(text_batch.numpy()[i])
print(label_batch.numpy()[i])b'an illegal immigrant resists the social support system causing dire consequences for many. well filmed and acted even though the story is a bit forced, yet the slow pacing really sets off the conclusion. the feeling of being lost in the big city is effectively conveyed. the little person lost in the big society is something to which we can all relate, but i cannot endorse going out of your way to see this movie.'
0
b"to get in touch with the beauty of this film pay close attention to the sound track, not only the music, but the way all sounds help to weave the imagery. how beautifully the opening scene leading to the expulsion of gino establishes the theme of moral ambiguity! note the way music introduces the characters as we are led inside giovanna's marriage. don't expect to find much here of the political life of italy in 1943. that's not what this is about. on the other hand, if you are susceptible to the music of images and sounds, you will be led into a word that reaches beyond neo-realism. by the end of the film we there are moments antonioni-like landscape that has more to do with the inner life of the characters than with real places. this is one of my favorite visconti films."
1
b'"hollywood hotel" has relationships to many films like "ella cinders" and "merton of the movies" about someone winning a contest including a contract to make films in hollywood, only to find the road to stardom either paved with pitfalls or non-existent. in fact, as i was watching it tonight, on turner classic movies, i was considering whether or not the authors of the later musical classic "singing in the rain" may have taken some of their ideas from "hollywood hotel", most notably a temperamental leading lady star in a movie studio and a conclusion concerning one person singing a film score while another person got the credit by mouthing along on screen.<br /><br />"hollywood hotel" is a fascinating example of movie making in the 1930s. among the supporting players is louella parsons, playing herself (and, despite some negative comments i\'ve seen, she has a very ingratiating personality on screen and a natural command of her lines). she is not the only real person in the script. make-up specialist perc westmore briefly appears as himself to try to make one character resemble another.<br /><br />this film also was one of the first in the career of young mr. ronald reagan, playing a radio interviewer at a movie premiere. reagan actually does quite nicely in his brief scenes - particularly when he realizes that nobody dick powell is about to take over the microphone when it should be used with more important people.<br /><br />dick powell has won a hollywood contract in a contest, and is leaving his job as a saxophonist in benny goodman\'s band. the beginning of this film, by the way, is quite impressive, as the band drives in a parade of trucks to give a proper goodbye to powell. they end up singing "hooray for hollywood". the interesting thing about this wonderful number is that a lyric has been left out on purpose. throughout the johnny mercer lyrics are references to such hollywood as max factor the make-up king, rin tin tin, and even a hint of tarzan. but the original song lyric referred to looking like tyrone power. obviously jack warner and his brothers were not going to advertise the leading man of 20th century fox, and the name donald duck was substituted. in any event the number showed the singers and instrumentalists of goodman\'s orchestra at their best. so did a later five minute section of the film, where the band is rehearsing.<br /><br />powell leaves the band and his girl friend (frances langford) and goes to hollywood, only to find he is a contract player (most likely for musicals involving saxophonists). he is met by allen joslyn, the publicist of the studio (the owner is grant mitchell). joslyn is not a bad fellow, but he is busy and he tends to slough off people unless it is necessary to speak to them. he parks powell at a room at the hollywood hotel, which is also where the studio\'s temperamental star (lola lane) lives with her father (hugh herbert), her sister (mabel todd), and her sensible if cynical assistant (glenda farrell). lane is like jean hagen in "singing in the rain", except her speaking voice is good. her version of "dan lockwood" is one "alexander dupre" (alan mowbray, scene stealing with ease several times). the only difference is that mowbray is not a nice guy like gene kelly was, and lane (when not wrapped up in her ego) is fully aware of it. having a fit on being by-passed for an out-of-the ordinary role she wanted, she refuses to attend the premiere of her latest film. joslyn finds a double for her (lola\'s real life sister rosemary lane), and rosemary is made up to play the star at the premiere and the follow-up party. but she attends with powell (joslyn wanting someone who doesn\'t know the real lola). this leads to powell knocking down mowbray when the latter makes a pest of himself. but otherwise the evening is a success, and when the two are together they start finding each other attractive.<br /><br />the complications deal with lola coming back and slapping powell in the face, after mowbray complains he was attacked by powell ("and his gang of hoodlums"). powell\'s contract is bought out. working with photographer turned agent ted healey (actually not too bad in this film - he even tries to do a jolson imitation at one point), the two try to find work, ending up as employees at a hamburger stand run by bad tempered edgar kennedy (the number of broken dishes and singing customers in the restaurant give edgar plenty of time to do his slow burns with gusto). eventually powell gets a "break" by being hired to be dupre\'s singing voice in a rip-off of "gone with the wind". this leads to the final section of the film, when rosemary lane, herbert, and healey help give powell his chance to show it\'s his voice, not mowbrays.<br /><br />it\'s quite a cute and appealing film even now. the worst aspects are due to it\'s time. several jokes concerning african-americans are no longer tolerable (while trying to photograph powell as he arrives in hollywood, healey accidentally photographs a porter, and mentions to joslyn to watch out, powell photographs too darkly - get the point?). also a bit with curt bois as a fashion designer for lola lane, who is (shall we say) too high strung is not very tolerable either. herbert\'s "hoo-hoo"ing is a bit much (too much of the time) but it was really popular in 1937. and an incident where healey nearly gets into a brawl at the premiere (this was one of his last films) reminds people of the tragic, still mysterious end of the comedian in december 1937. but most of the film is quite good, and won\'t disappoint the viewer in 2008.'
1对数据进行标记
我们将使用 keras_nlp.tokenizers.WordPieceTokenizer 层对文本进行标记化。keras_nlp.tokenizers.WordPieceTokenizer 接收一个 WordPiece 词汇表,并具有对文本进行标记化和对标记序列进行去标记化的函数。
在定义标记化器之前,我们首先需要在现有的数据集上对其进行训练。WordPiece 标记化算法是一种子词标记化算法;在语料库上对它进行训练,就能得到一个子词词汇表。子词标记化算法是单词标记化算法(单词标记化算法需要非常大的词汇量才能很好地覆盖输入单词)和字符标记化算法(字符并不像单词那样真正编码意义)之间的折衷方案。幸运的是,KerasNLP 使用 keras_nlp.tokenizers.compute_word_piece_vocabulary 实用程序可以非常简单地在语料库上训练 WordPiece。
注:FNet 的官方实现使用 SentencePiece Tokenizer。
def train_word_piece(ds, vocab_size, reserved_tokens):
word_piece_ds = ds.unbatch().map(lambda x, y: x)
vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
word_piece_ds.batch(1000).prefetch(2),
vocabulary_size=vocab_size,
reserved_tokens=reserved_tokens,
)
return vocab每个词汇都有一些特殊的保留标记。我们有两个这样的标记:
"[PAD]"标记- 填充标记。当输入序列长度短于最大序列长度时,填充标记会被附加到输入序列长度上。"[UNK]" 未知标记。- 未知标记。
reserved_tokens = ["[PAD]", "[UNK]"]
train_sentences = [element[0] for element in train_ds]
vocab = train_word_piece(train_ds, VOCAB_SIZE, reserved_tokens)我们来看看tokens!
print("Tokens: ", vocab[100:110])Tokens: ['à', 'á', 'â', 'ã', 'ä', 'å', 'æ', 'ç', 'è', 'é']现在,让我们定义标记符。我们将使用上文训练过的词汇来配置标记符。我们将定义最大序列长度,这样,如果序列长度小于指定的序列长度,所有序列都会被填充为相同长度。否则,序列将被截断。
tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
vocabulary=vocab,
lowercase=False,
sequence_length=MAX_SEQUENCE_LENGTH,
)让我们尝试对数据集中的一个样本进行标记化!为了验证文本的标记化是否正确,我们还可以将标记列表重新标记为原始文本。
input_sentence_ex = train_ds.take(1).get_single_element()[0][0]
input_tokens_ex = tokenizer(input_sentence_ex)
print("Sentence: ", input_sentence_ex)
print("Tokens: ", input_tokens_ex)
print("Recovered text after detokenizing: ", tokenizer.detokenize(input_tokens_ex))Sentence: tf.Tensor(b'this picture seemed way to slanted, it\'s almost as bad as the drum beating of the right wing kooks who say everything is rosy in iraq. it paints a picture so unredeemable that i can\'t help but wonder about it\'s legitimacy and bias. also it seemed to meander from being about the murderous carnage of our troops to the lack of health care in the states for ptsd. to me the subject matter seemed confused, it only cared about portraying the military in a bad light, as a) an organzation that uses mind control to turn ordinary peace loving civilians into baby killers and b) an organization that once having used and spent the bodies of it\'s soldiers then discards them to the despotic bureacracy of the v.a. this is a legitimate argument, but felt off topic for me, almost like a movie in and of itself. i felt that "the war tapes" and "blood of my brother" were much more fair and let the viewer draw some conclusions of their own rather than be beaten over the head with the film makers viewpoint. f-', shape=(), dtype=string) Tokens: [ 145 576 608 228 140 58 13343 13 143 8 58 360 148 209 148 137 9759 3681 139 137 344 3276 50 12092 164 169 269 424 141 57 2093 292 144 5115 15 143 7890 40 576 170 2970 2459 2412 10452 146 48 184 8 59 478 152 733 177 143 8 58 4060 8069 13355 138 8557 15 214 143 608 140 526 2121 171 247 177 137 4726 7336 139 395 4985 140 137 711 139 3959 597 144 137 1844 149 55 1175 288 15 140 203 137 1009 686 608 1701 13 143 197 3979 177 2514 137 1442 144 40 209 776 13 148 40 10 168 14198 13928 146 1260 470 1300 140 604 2118 2836 1873 9991 217 1006 2318 138 41 10 168 8469 146 422 400 480 138 1213 137 2541 139 143 8 58 1487 227 4319 10720 229 140 137 6310 8532 862 41 2215 6547 10768 139 137 61 15 40 15 145 141 40 7738 4120 13 152 569 260 3297 149 203 13 360 172 40 150 144 138 139 561 15 48 569 146 3 137 466 6192 3 138 3 665 139 193 707 3 204 207 185 1447 138 417 137 643 2731 182 8421 139 199 342 385 206 161 3920 253 137 566 151 137 153 1340 8845 15 45 14 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] Recovered text after detokenizing: tf.Tensor(b'this picture seemed way to slanted , it \' s almost as bad as the drum beating of the right wing kooks who say everything is rosy in iraq . it paints a picture so unredeemable that i can \' t help but wonder about it \' s legitimacy and bias . also it seemed to meander from being about the murderous carnage of our troops to the lack of health care in the states for ptsd . to me the subject matter seemed confused , it only cared about portraying the military in a bad light , as a ) an organzation that uses mind control to turn ordinary peace loving civilians into baby killers and b ) an organization that once having used and spent the bodies of it \' s soldiers then discards them to the despotic bureacracy of the v . a . this is a legitimate argument , but felt off topic for me , almost like a movie in and of itself . i felt that " the war tapes " and " blood of my brother " were much more fair and let the viewer draw some conclusions of their own rather than be beaten over the head with the film makers viewpoint . f - [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]', shape=(), dtype=string)
格式化数据集
接下来,我们要将数据集格式化,以提供给模型。我们需要对文本进行标记化。
def format_dataset(sentence, label):
sentence = tokenizer(sentence)
return ({"input_ids": sentence}, label)
def make_dataset(dataset):
dataset = dataset.map(format_dataset, num_parallel_calls=tf.data.AUTOTUNE)
return dataset.shuffle(512).prefetch(16).cache()
train_ds = make_dataset(train_ds)
val_ds = make_dataset(val_ds)
test_ds = make_dataset(test_ds)建立模型
现在,让我们进入激动人心的部分--定义模型!我们首先需要一个嵌入层,也就是将输入序列中的每个标记映射到一个向量的层。这个嵌入层可以随机初始化。我们还需要一个位置嵌入层,对序列中的词序进行编码。惯例是将这两个嵌入层相加,即求和。KerasNLP 有一个 keras_nlp.layers.TokenAndPositionEmbedding 层,可以为我们完成上述所有步骤。
我们的 FNet 分类模型由三个 keras_nlp.layers.FNetEncoder 层和一个 keras.layers.Dense 层组成。
注:对于 FNet,屏蔽填充标记对结果的影响微乎其微。在正式实施中,不屏蔽填充标记。
input_ids = keras.Input(shape=(None,), dtype="int64", name="input_ids")
x = keras_nlp.layers.TokenAndPositionEmbedding(
vocabulary_size=VOCAB_SIZE,
sequence_length=MAX_SEQUENCE_LENGTH,
embedding_dim=EMBED_DIM,
mask_zero=True,
)(input_ids)
x = keras_nlp.layers.FNetEncoder(intermediate_dim=INTERMEDIATE_DIM)(inputs=x)
x = keras_nlp.layers.FNetEncoder(intermediate_dim=INTERMEDIATE_DIM)(inputs=x)
x = keras_nlp.layers.FNetEncoder(intermediate_dim=INTERMEDIATE_DIM)(inputs=x)
x = keras.layers.GlobalAveragePooling1D()(x)
x = keras.layers.Dropout(0.1)(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
fnet_classifier = keras.Model(input_ids, outputs, name="fnet_classifier")/home/matt/miniconda3/envs/keras-io/lib/python3.10/site-packages/keras/src/layers/layer.py:861: UserWarning: Layer 'f_net_encoder' (of type FNetEncoder) was passed an input with a mask attached to it. However, this layer does not support masking and will therefore destroy the mask information. Downstream layers will not see the mask.
warnings.warn(训练我们的模型
我们将使用准确率来监控验证数据的训练进度。让我们对模型进行 3 个历元的训练。
fnet_classifier.summary()
fnet_classifier.compile(
optimizer=keras.optimizers.Adam(learning_rate=0.001),
loss="binary_crossentropy",
metrics=["accuracy"],
)
fnet_classifier.fit(train_ds, epochs=EPOCHS, validation_data=val_ds)Model: "fnet_classifier"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ input_ids (InputLayer) │ (None, None) │ 0 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ token_and_position_embedding │ (None, None, 128) │ 1,985,536 │ │ (TokenAndPositionEmbedding) │ │ │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ f_net_encoder (FNetEncoder) │ (None, None, 128) │ 132,224 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ f_net_encoder_1 (FNetEncoder) │ (None, None, 128) │ 132,224 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ f_net_encoder_2 (FNetEncoder) │ (None, None, 128) │ 132,224 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ global_average_pooling1d │ (None, 128) │ 0 │ │ (GlobalAveragePooling1D) │ │ │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ dropout (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ dense (Dense) │ (None, 1) │ 129 │ └─────────────────────────────────┴───────────────────────────┴────────────┘Total params: 2,382,337 (9.09 MB)Trainable params: 2,382,337 (9.09 MB)Non-trainable params: 0 (0.00 B)
我们获得了约 92% 的训练准确率和约 85% 的验证准确率。此外,对于 3 个epochs,训练模型大约需要 86 秒(在 Colab 上使用 16 GB Tesla T4 GPU)。
让我们来计算一下测试精度。
fnet_classifier.evaluate(test_ds, batch_size=BATCH_SIZE) 391/391 ━━━━━━━━━━━━━━━━━━━━ 3s 5ms/step - accuracy: 0.8412 - loss: 0.4281
[0.4198716878890991, 0.8427909016609192]与变换器模型比较
让我们将 FNet 分类器模型与 Transformer 分类器模型进行比较。
我们保持所有参数/超参数不变。例如,我们使用三个 TransformerEncoder 层。
我们将人头数量设为 2。
NUM_HEADS = 2
input_ids = keras.Input(shape=(None,), dtype="int64", name="input_ids")
x = keras_nlp.layers.TokenAndPositionEmbedding(
vocabulary_size=VOCAB_SIZE,
sequence_length=MAX_SEQUENCE_LENGTH,
embedding_dim=EMBED_DIM,
mask_zero=True,
)(input_ids)
x = keras_nlp.layers.TransformerEncoder(
intermediate_dim=INTERMEDIATE_DIM, num_heads=NUM_HEADS
)(inputs=x)
x = keras_nlp.layers.TransformerEncoder(
intermediate_dim=INTERMEDIATE_DIM, num_heads=NUM_HEADS
)(inputs=x)
x = keras_nlp.layers.TransformerEncoder(
intermediate_dim=INTERMEDIATE_DIM, num_heads=NUM_HEADS
)(inputs=x)
x = keras.layers.GlobalAveragePooling1D()(x)
x = keras.layers.Dropout(0.1)(x)
outputs = keras.layers.Dense(1, activation="sigmoid")(x)
transformer_classifier = keras.Model(input_ids, outputs, name="transformer_classifier")
transformer_classifier.summary()
transformer_classifier.compile(
optimizer=keras.optimizers.Adam(learning_rate=0.001),
loss="binary_crossentropy",
metrics=["accuracy"],
)
transformer_classifier.fit(train_ds, epochs=EPOCHS, validation_data=val_ds)Model: "transformer_classifier"┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ input_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ token_and_position… │ (None, None, 128) │ 1,985,… │ input_ids[0][0] │ │ (TokenAndPositionE… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ transformer_encoder │ (None, None, 128) │ 198,272 │ token_and_position_… │ │ (TransformerEncode… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ transformer_encode… │ (None, None, 128) │ 198,272 │ transformer_encoder… │ │ (TransformerEncode… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ transformer_encode… │ (None, None, 128) │ 198,272 │ transformer_encoder… │ │ (TransformerEncode… │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ not_equal_1 │ (None, None) │ 0 │ input_ids[0][0] │ │ (NotEqual) │ │ │ │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ global_average_poo… │ (None, 128) │ 0 │ transformer_encoder… │ │ (GlobalAveragePool… │ │ │ not_equal_1[0][0] │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ dropout_4 (Dropout) │ (None, 128) │ 0 │ global_average_pool… │ ├─────────────────────┼───────────────────┼─────────┼──────────────────────┤ │ dense_1 (Dense) │ (None, 1) │ 129 │ dropout_4[0][0] │ └─────────────────────┴───────────────────┴─────────┴──────────────────────┘Total params: 2,580,481 (9.84 MB)Trainable params: 2,580,481 (9.84 MB)Non-trainable params: 0 (0.00 B)
Epoch 1/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 14s 38ms/step - accuracy: 0.5895 - loss: 0.7401 - val_accuracy: 0.8912 - val_loss: 0.2694
Epoch 2/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 9s 29ms/step - accuracy: 0.9051 - loss: 0.2382 - val_accuracy: 0.8853 - val_loss: 0.2984
Epoch 3/3
313/313 ━━━━━━━━━━━━━━━━━━━━ 9s 29ms/step - accuracy: 0.9496 - loss: 0.1366 - val_accuracy: 0.8730 - val_loss: 0.3607
<keras.src.callbacks.history.History at 0x7feaf9c56ad0>训练准确率约为 94%,验证准确率约为 86.5%。模型训练耗时约 146 秒(在 Colab 上使用 16GB Tesla T4 GPU)。
让我们来计算一下测试精度。
transformer_classifier.evaluate(test_ds, batch_size=BATCH_SIZE) 391/391 ━━━━━━━━━━━━━━━━━━━━ 4s 11ms/step - accuracy: 0.8399 - loss: 0.4579
[0.4496161639690399, 0.8423193097114563]让我们制作一张表格,比较这两种模型。
我们可以看到,FNet 明显加快了我们的运行时间(1.7 倍),而在总体准确性方面只做出了很小的牺牲(下降了 0.75%)。
| FNet Classifier | Transformer Classifier | |
|---|---|---|
| Training Time | 86 seconds | 146 seconds |
| Train Accuracy | 92.34% | 93.85% |
| Validation Accuracy | 85.21% | 86.42% |
| Test Accuracy | 83.94% | 84.69% |
| #Params | 2,321,921 | 2,520,065 |